I just published my first R package, ravelRy! You can read more about it in the introduction post here.

This post is part of a series that will explore data pulled from the Ravelry.com API into R using the package. Here, we'll pull yarn data and explore how different types of fibers appear together in popular yarn blends.
The finished product:
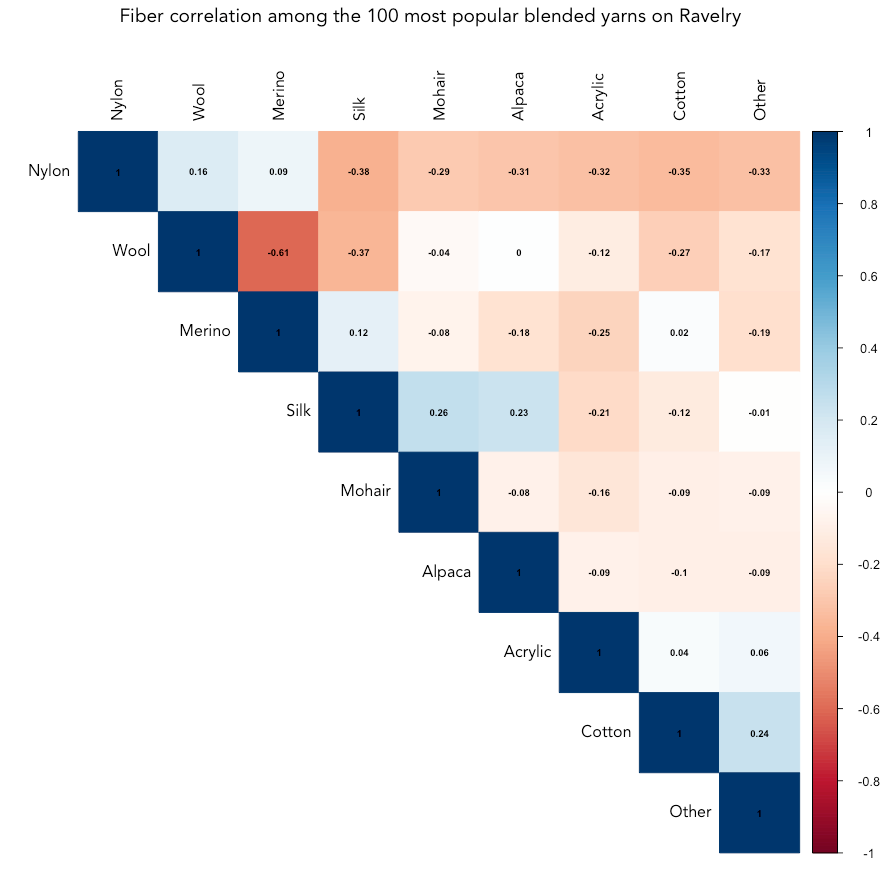
Note that is a small sample of yarn for demonstration (n = 100 out of 100,000+ entries on Ravelry) so the correlation plot above shouldn't be considered exhaustive by any means, but rather a look at the how fibers co-occur in the 100 most popular blended yarns.
The most likely combinations of fibers in popular yarn are silk and mohair, silk/alpaca, cotton/other, and nylon/wool. Wool and merino are the least likely blend, followed by nylon/silk, wool/silk, and nylon/cotton.
The divergence of merino and wool is a simple one - merino is a type of wool! It's not likely to see a mix of merino wool with another type of wool because it wouldn't offer any benefits typically given by a blend.
Silk is often blended with mohair and alpaca to add strength, sheen and smoothness to the warm and robust, but often itchy, animal fibers. Nylon is often the choice for adding to wool for similar reasons - it add strength and durability without diminishing the soft warmth of wool.
Silk and wool blends are not uncommon, so it's interesting to see the pair diverging in the top 100 most popular yarns! Silk and merino have a positive correlation, however, which may explain it - when silk is blended with wool, it's probably going to be merino wool.
See below for step-by-step R code to build this plot.
Installation
First, download the package. You can either download from CRAN or from the development version on Github.
install.packages("ravelRy")
devtools::install_github("walkerkq/ravelRy")
Authenticating
To access the API, you'll need a free developer account, which you can create at https://www.ravelry.com/pro/developer. Then, create an app with basic read only authentication to receive a username and password.
You can either set the environment variables RAVELRY_USERNAME and RAVELRY_PASSWORD in your .Renviron file, or via the R console using the ravelry_auth function.
ravelry_auth(key = 'username') # you will be prompted to enter your username
ravelry_auth(key = 'password') # you will be prompted to enter your password Getting data
Next, search for yarn.
yarns <- search_yarn(page_size = 100, sort = 'projects', fiberc = '2') This query limits the results to the top 100 yarns used in the most projects that have two fiber types using the parameters:
page_size= 100,sort = 'projects'to sort by yarn used in the most projects,- and passing a filter parameter,
fiberc = '2'to the...portion of the function.
You can discover new filter parameters by toggling filters in the yarn search on the site and inspecting the URL.
Note that there are more than 100,000 yarn entries on Ravelry! This sample (n = 100) is really small and definitely not representative of ALL yarn.
Next, pass the returned ids to the get_yarns function to return features for each result.
yarn_details <- get_yarns(ids = yarns$id)Which returns a data.frame with 26 variables, 8 of which are list columns containing tibbles.
str(yarn_details, max.level = 0)
'data.frame': 100 obs. of 26 variables:
$ discontinued : logi FALSE FALSE FALSE FALSE ...
$ gauge_divisor : chr "" "" "1" "1" ...
$ grams : chr "150" "50" "100" "100" ...
$ id : int 24750 74690 60478 71337 ...
$ machine_washable : chr "TRUE" "" "TRUE" "TRUE" ...
$ max_gauge : chr "" "" "8" "5" ...
$ min_gauge : chr "" "" "7" "4.5" ...
$ name : chr "Sockenwolle 80/20 Twin" "DROPS Lace " ...
$ permalink : chr "rohrspatz--wollmeise-sockenwolle-80-20-twin" ...
$ rating_average : num 4.69 4.49 4.44 4.18 ...
$ rating_count : int 4370 1873 4072 2388 ...
$ rating_total : int 20484 8401 18060 9984 ...
$ texture : chr "plied" "plied" "plied" "singles" ...
$ thread_size : chr "" "" "" "" ...
$ wpi : chr "" "" "" "" ...
$ yardage : int 510 437 462 198 ...
$ notes_html : chr "\n<p>New sock yarn from Wollmeise."| __truncated__ ...
$ min_needle_size : List of 100
$ max_needle_size : List of 100
$ min_hook_size : List of 100
$ max_hook_size : List of 100
$ personal_attributes : chr "" "" "" "" ...
$ yarn_weight : List of 100
$ yarn_company : List of 100
$ yarn_fibers : List of 100
$ photos : List of 100To explore fiber types of each yarn, we'll need to unnest the yarn_fibers column using tidyr::unnest.
yarn_details %>%
select(yarn_fibers, id) %>%
unnest(yarn_fibers, names_sep = '_') %>%
str()
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 201 obs. of 14 variables:
$ yarn_fibers_id : int 27616 27617 ...
$ yarn_fibers_percentage : int 20 80 ...
$ yarn_fibers_fiber_type.animal_fiber : logi FALSE TRUE ...
$ yarn_fibers_fiber_type.id : int 2 24 ...
$ yarn_fibers_fiber_type.name : chr "Nylon" "Merino" ...
$ yarn_fibers_fiber_type.synthetic : logi TRUE FALSE ...
$ yarn_fibers_fiber_type.vegetable_fiber : logi FALSE FALSE ...
$ yarn_fibers_fiber_category.id : int 216 22 ...
$ yarn_fibers_fiber_category.name : chr "Nylon / Polyamide" ...
$ yarn_fibers_fiber_category.permalink : chr "nylon" "merino" ...
$ yarn_fibers_fiber_category.parent.id : int 207 1 ...
$ yarn_fibers_fiber_category.parent.name : chr "Manufactured Fibers" ...
$ yarn_fibers_fiber_category.parent.permalink : chr "manufactured-fibers" ...
$ id : int 24750 24750 ...To prepare for computing the correlation and plotting, we should determine a threshold for which fibers will be included. Because our sample is small, it's possible that a fiber type like Bamboo could appear just once. Here, I have restricted to the top ten fibers appearing at least 5 times (which for our sample results in only 8 fibers).
Then, I bucket the remaining fibers into the category Other and use tidyr::pivot_wider to create a wide data.frame with a row for each yarn (id), columns for each fiber type, and values reflecting the percentage of that fiber in the yarn.
To prepare for computing the correlation, I drop the id, replace NA values with 0s, and all other values with 1s, since we are interested in which appear together and not necessarily the relationship between types and percentages. Finally, compute the correlation and plot using corrplot.
# get the top 10 fiber types appearing at least 5 times
top_fiber_types <- yarn_details %>%
unnest(yarn_fibers, names_sep = '_') %>%
count(yarn_fibers_fiber_type.name) %>%
filter(n > 5) %>%
arrange(desc(n)) %>%
slice(1:10)
# unnest the yarn_fibers column, bucket fiber names, and spread wide
yarn_fibers_wide <- yarn_details %>%
unnest(yarn_fibers, names_sep = '_') %>%
mutate(yarn_fiber_name = ifelse(yarn_fibers_fiber_type.name %in% top_fiber_types$yarn_fibers_fiber_type.name,
yarn_fibers_fiber_type.name,
'Other')) %>%
pivot_wider(id_cols = 'id',
names_from = 'yarn_fiber_name',
values_from = 'yarn_fibers_percentage',
values_fn = list(yarn_fibers_percentage = sum))
# compute correlation and plot
yarn_fibers_wide %>%
select(-id) %>%
mutate_if(is.numeric, function(x) ifelse(is.na(x), 0, 1)) %>%
cor() %>%
corrplot::corrplot(type = 'upper',
method = 'color',
order = 'hclust',
tl.col = 'black',
addCoef.col = 'black',
number.cex = 0.75,
main = 'Fiber correlation among the 100 most popular blended yarns on Ravelry',
family = 'Avenir')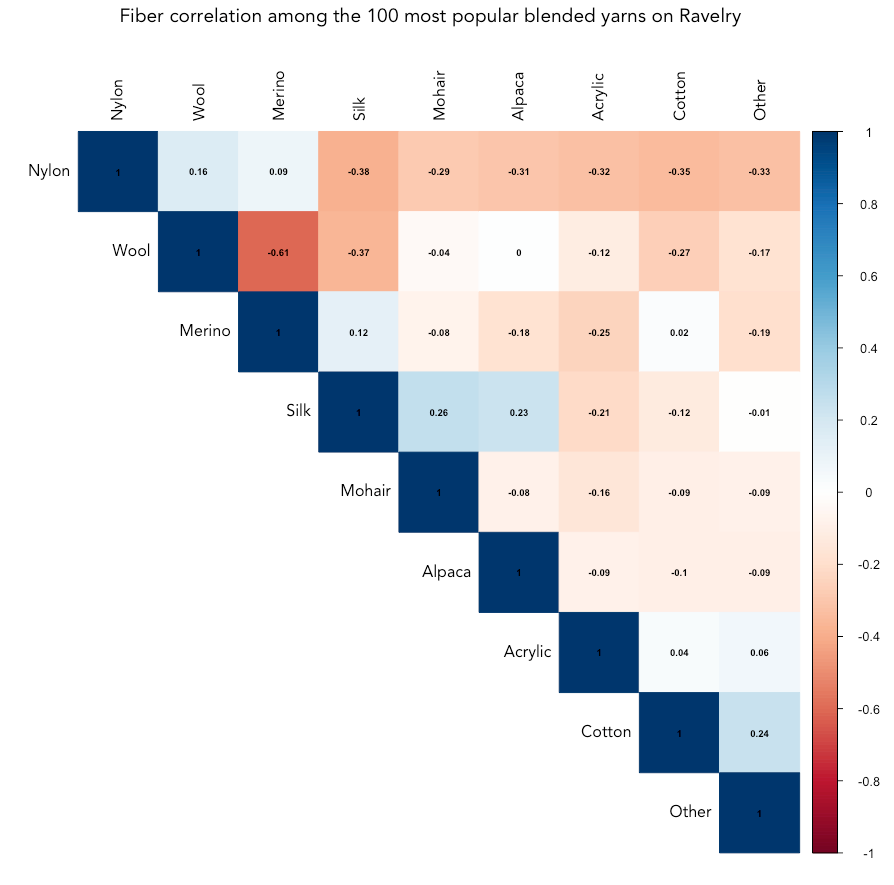
This post is part of a series that will explore data pulled from the Ravelry.com API into R using the ravelRy package.